System description
Features
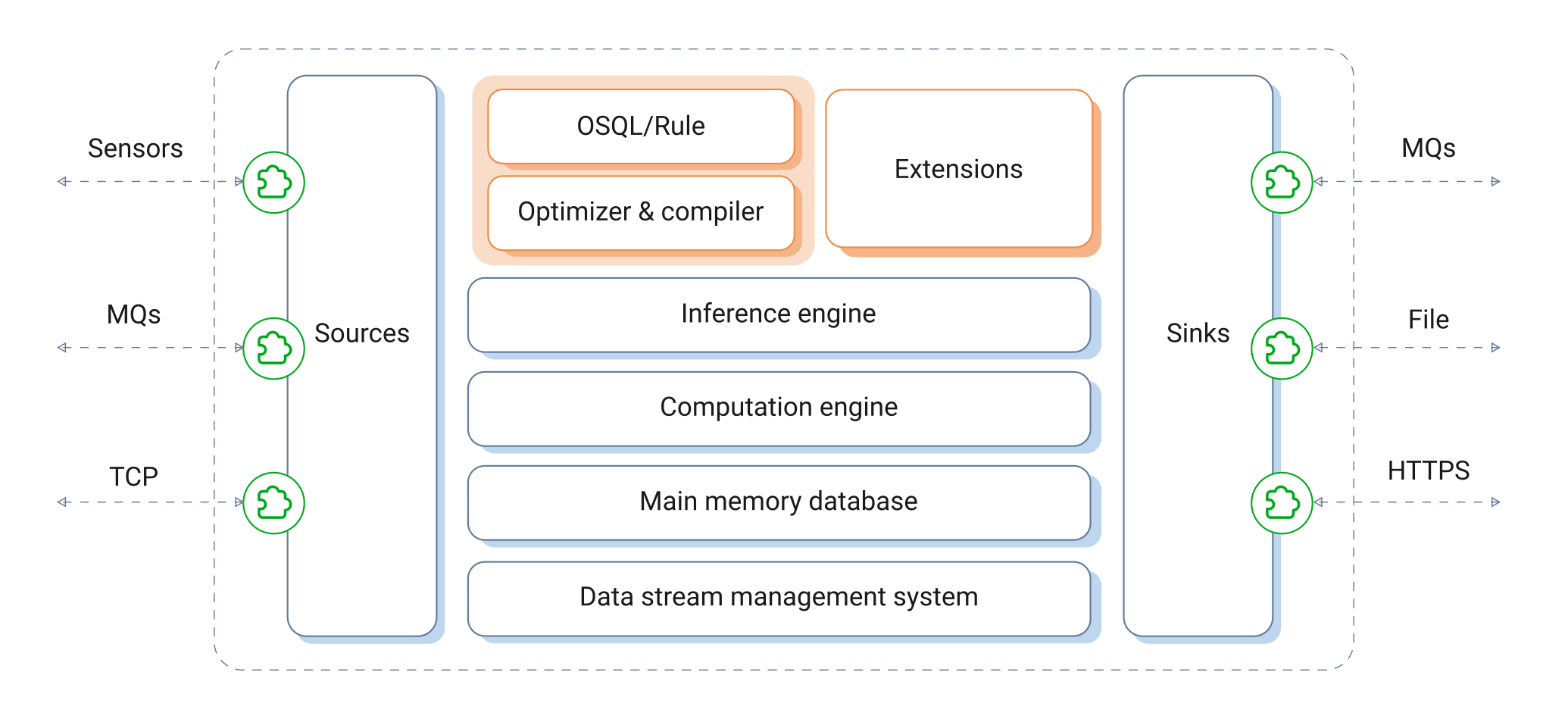
SA Engine consists of a main-memory database, a computational engine, a data stream processor, and an inference engine. Implemented on edge devices these components allow edge analytics directly on the edge devices.
The same runtime of SA Engine is used both in edge devices and in servers used to control and interact with the edge devices. Only having a single architecture for server and client applications makes the handling easier since the APIs, communication protocols and data types are the same for all applications in the platform chain. Also, since SA Engine is using the same runtime on all devices, there is no translation or reimplementation of models when they go from lab to production.
The incoming data streams can come from a wide range of sources, such as sensors, messaging services, serial ports, or message busses. It can also be a data stream produced by software on the device. There is a library of predefined wrappers to interoperate with common data infrastructures and the user can easily develop new wrappers for custom data sources. The wrappers use mediator models to translate the data into a universal data ontology SA Engine uses to homogenize data from heterogenous data streams. Mediation can be, e.g., mapping local names of sensors to a universally known nomenclature, measurement unit conversions, or calibrations of local measurements.
To analyze streaming data on a very high and user-oriented level, SA Engine allows analysts and engineers to develop computations, filters and transformations over data using a declarative queries in a seamless extension of SQL called OSQL (Object Stream Query Language). An OSQL query that continuously makes computations or filtering over measurements in a data stream is called a continuous query (CQ). With OSQL, computations and filters over real-time streaming data are defined as mathematical formulas and expressions called stream models. A stream model is a set of definitions of mathematical functions, filters, and other expressions over a stream of measurements. Stream models can combine streams using fusion queries and also stack multiple computations and algorithms to create a flexible analytics pipeline. This is important since machine learning requires pre-processing of sensor data before applying the learned inference algorithm, followed by post-processing of the inferred knowledge. With SA Engine both pre and post-processing are easily expressed using the powerful object stream filtering, transformation and mathematical/statistical analytics capabilities of OSQL. The result of a continuous query or stream model is a real-time object stream of processed and filtered measurements.
The system includes a deep learning subsystem, SANN, where TensorFlow neural network (NN) models can be automatically translated into an internal binary SANN representation and pushed out to the edge databases. Once stored in an edge database the SANN inference engine can use the NN models to analyze local sensor readings, e.g., to detect anomalies in sensor data streams. SANN furthermore allows to continue training and even building neural networks on edge devices. Thus, centrally trained models can be further retrained and modified on edge devices to adapt their behavior to their environment.
When the data stream has been processed by the stream models, the processed and filtered streams can either be consumed locally or they can be forwarded to other systems, e.g., for permanent central storage, batch analysis or monitoring, through one of the many communication technologies supported by SA Engine, such as Kafka, MQTT, EventHub, RabbitMQT, HTTP/REST, Websocket, TCP etc. If the desired method of sending data is not in the "out of the box" supported list the method can easily be integrated using the APIs to one of SA Engine's supported extension languages (Lisp, C, C++, Java, Python).
On server computers SA Engine systems can also be configured as stream servers. This enables servers to collect data from edges and combine and forward the data to other server-based systems and users. Stream servers can aggregate and analyze data from multiple devices, and forward received data to other systems, e.g. for permanent central storage or batch analysis.
Both stream models and user data are stored in very fast object-oriented in-memory databases residing on the edge devices and in the stream servers. These databases are important for data stream processing, which usually involves matching in real-time fast flowing stream objects against data in a database. For example, to locally determine that the frequency spectrum of a measured vibration may later destroy an edge device, the frequencies measured by vibration sensors on a device is matched against the local database of resonance frequencies in the device.
The system includes a large library of predefined OSQL-functions for mathematical/statistical computations, object stream filtering and transformation, signal processing, model and data management, and much more. The function library is continuously extended for new customer needs and it is easy to define and deploy new user functions on the fly.
Existing algorithms and libraries implemented in a regular programming language, such as C or Java, can be plugged into the system as foreign functions (also called extensions) that implement OSQL functions in some external programming language using language specific APIs. The foreign functions can then be transparently used in OSQL queries and expressions. For example, a large library of basic mathematical, statistical, and machine learning algorithms are implemented as foreign OSQL functions in C and Lisp.
The core system
The SA Engine core system provides general data analytics and inference capabilities to the device or computer where it is running. The core system is written in C99 and is not depending on any other system. It is agnostic to hardware, OS, and communication infrastructure used by the device or the computer. This has enabled porting it to many different kinds of devices, computers and OSes.
The system is designed to be easily integrated with other systems and extended with models and plug-ins. The figure below illustrates how the SA Engine core system is extensible by user models calling interfaces to external systems and accessing different kinds of data sources.
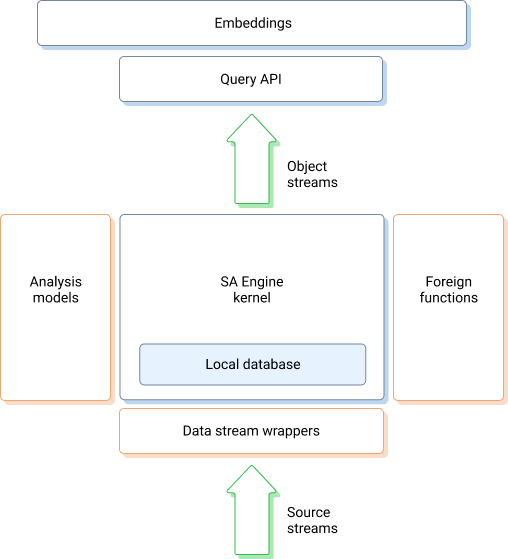
The main part of the system is the SA Engine kernel (center). It provides the generic capabilities needed for real-time data stream analytics. In contains the computational engine, data stream processor, and inference engine. An important component of the SA Engine kernel is the main memory local database where, e.g., analysis models and device meta-data are stored. The SA Engine kernel includes a powerful query processor and optimizer to search and analyze data and models in the local database.
The green arrows indicate streams. Sensors and software produce inflowing source streams that are injected into the SA Engine system, which transforms them into one or several outflowing object streams.
A source stream may be implemented as accesses to a raw sensor interface on the computer or edge device where the SA Engine kernel is running. A source stream can also be a data stream produced by software. In distributed configurations the source stream may be received from another computer or device than the kernel, in which case some communication infrastructure (e.g. TCP) is used.
Analogously, the outflowing object streams may be sent to other systems and application using some communication infrastructure. Large distributed systems of SA Engine instances can be configured in which SA Engine peers produce object streams consumed by other SA Engine peers as source streams. On the edge devices the object stream elements can also be sent directly to actuators mounted on the device.
Running SA Engine bare bone or with OS
In the figure below a layer diagram of SA Engine running on a microcontroller is shown. If no operating system is present on the device, SA Engine includes necessary hardware drivers.
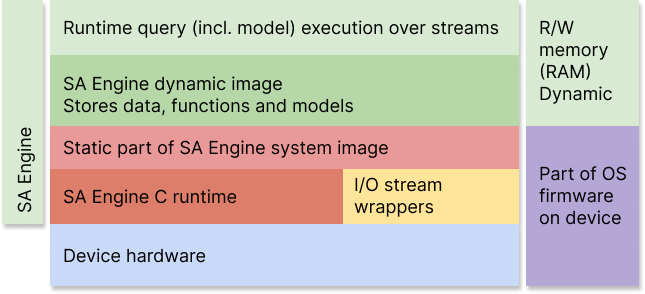
A layer diagram of SA Engine running on a microcontroller without operating system.
The figure below shows how SA Engine runs on a regular operating system on machines such as telematics control units or cloud nodes, including containers.
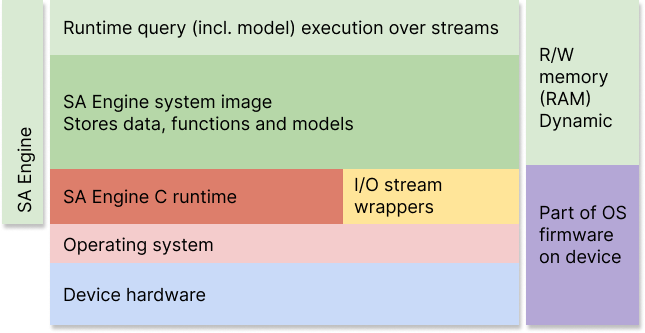
Layer diagram of SA Engine running on a device with an operating system included.
Plugins
As mentioned in the previous section, SA Engine is a highly extensible system where different kinds of plug-ins can be added without changing other parts of the system. In the figure above the plug-ins are marked in peach color, where foreign functions is the most tightly and system-oriented plug-in implementation, before data stream wrappers, followed by analysis models as the least tightly and system-oriented plugin implementation.
Analysis models are models that specify transformations, filters, computations and inferences over the source streams to produce object streams as results. The analysis models are specified by engineers and analysts. It is not required to have deep programming skills or detailed knowledge about the SA Engine kernel to define such models. The analysis models are defined using the very powerful query language OSQL as a glue to combine different kinds of models, algorithms, and engines. An analysis model is constituted as a set of OSQL functions and continuous query definitions stored in the local database.
OSQL can be extended through foreign functions, which define OSQL functions implemented in some regular programming language (e.g. C, Lisp or Java, see the language API documentation in the Reference section for more information). The foreign functions implement external algorithms, e.g. numerical, statistical, and inference algorithms, as plug-ins. They can be plugged into the kernel without modifying it. The algorithms can be used in analysis models to filter and transform the incoming data streams into derived object streams.
Foreign functions written in C, C++, and Lisp have full access to the kernel system allowing very powerful addition of capabilities to the kernel, for example to access file systems, making OS system calls, running deep learning inference engines, or accessing complex database managers. For high performance, the extensibility of SA Engine permits the direct representation of binary C data structures as OSQL objects without any transformations.
In order to access incoming data streams in CQs, data stream wrappers (see figure above) can be implemented as OSQL functions. Notice that only one such data stream wrapper needs to be implemented for each kind of incoming data stream; once implemented for a certain stream kind all such streams can be queried with OSQL. A data stream wrapper is defined as an OSQL wrapper function returning an object stream. Often the wrapper functions are implemented as foreign functions, but in many cases, they are defined completely in OSQL.
Data steam wrappers need to physically access an external data stream in order to convert each of its arriving data stream elements to a suitable data format for efficient and flexible processing by the SA Engine kernel. Different streams often represent their elements using different physical data structures, so the data stream wrappers usually convert the external data representations to a format already supported by the system. When needed, new physical data representations can be plugged in for customized representation of C data structures. The representation of specialized binary C formats can be can be used for very efficient processing of stream elements.
There is a built-in library of data stream wrappers for common infrastructures, e.g., for Kafka, Azure Event Hub, MQTT, CVS and JSON streams. The data streams will be infinite when they originate in a sensor. However, they can also be finite. For example, there is a special JDBC data stream wrapper available that handles the finite result from an SQL query passed as a wrapper function parameter through JDBC to a relational database.
Embeddings
The SA Engine kernel can be an embedding (see top of figure above) in other applications or systems that access object streams produced through a continuous query CQ API. The application program or system can run in the same process and address space as the SA Engine kernel, which is often case when running an embedded SA Engine on an edge device. Another common case is that an SA Engine system running on an edge device acts as a client to an SA Engine server running on some other computer or cluster communicated with using TCP or some other communication infrastructure. There are such interfaces to embeddings defined for common infrastructures such as CSV and JSON streams over TCP, Kafka and Azure Event Hub.
Federations
In order to manage massive amounts of SA Engine systems on IoT devices, the system can be scaled out to large distributed systems of communicating SA servers that can run on clusters, clouds, PCs or virtually any kind of computer. The figure below illustrates how edge devices with SA Engines on-board, called edge clients (ECs), are managed by SA servers (SASes) running in a cloud.
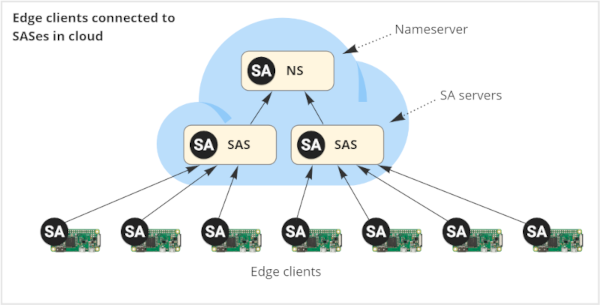
Depending on the size and configuration of an edge device, an edge client can be a Nanocore SA Engine, an embedded Nanocore SA Engine or a complete SA Engine system. The tiny configuration in the figure above has seven edge clients. The unique identity of each EC needs to be registered with an SAS running on some server in a cloud, container, PC, or as a separate process on the same computer as the EC. In the figure, there are two SASes running in a cloud where the seven ECs are registered. There is a special SAS keeping track of all the unique identities of each SAS called the nameserver (NS). Through the NS and the SASes all ECs can be reached.
Different instances of the SA Engine kernel running on different computers can communicate with SASes running on the same or some other computer. In particular each EC communicates with the SAS where it is registered. The SAS keeps some metadata about its ECs and can forward data and streams to other SASes.
It should be noticed that an edge client is not required to be continuously connected with its SAS, it only needs to registered with it. The actual connection to the device and generation of object streams is started and finished only when so required. If there is no active connection with its SAS the edge client runs autonomously.
The overall term SA Engine peer is used to denote any kernel system running either as an NS, SAS or EC. The universe of all peers is called a federation. In the figure above there is a federation of ten peers.
In general, a peer can be one of the following:
- It can be an embedded engine running on some device or computer.
- It can an edge client, EC, running on an edge device registered in a SAS.
- It can be a SA server, SAS, that coordinates communication with other peers.
- It can also be a nameserver, NS, which is a SAS that keeps track of all peers in a federation of SA Engine peers. The nameserver usually wraps a regular database where metadata about the peers is persisted.
In practice there can be a massive number of devices accessible through edge clients. It is therefore necessary to be able to scale out the numbers of peers to handle extremely large numbers of edge clients, from tens of thousands up to billions. This is handled by scaling out the number of edge clients registered in each SAS to thousands of edge clients and defining a hierarchy of several SAS levels.
The SASes and the NS can run on many different kinds of hardware and software configurations. In the simplest case they all run on a regular PC. In more scalable configurations each SAS can run in a separate container (e.g. Docker) and the NS along with a relational database (to hold identifiers of all peers in the federation, along with other meta-data such as what kind of equipment is accessible through each edge client, what kind of sensors they access, etc.) on a dedicated cluster. With such a scale-out, if the number of clients registered with each peer is 1000 and with two levels of SASes up to 10^9 peers can be handled. The relational database is not a bottleneck here as a limited amount of meta-data per peer will be stored there.
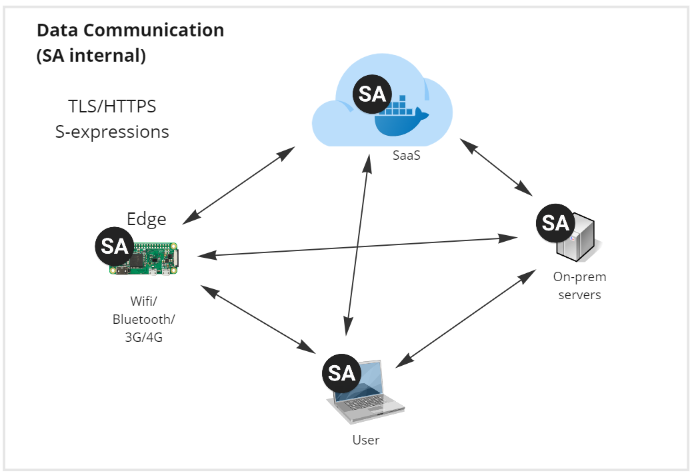
To communicate internally between instances SA Engine uses TLS/HTTPS and sends data and code as S-expressions.
This page is an extract from various resources. For more detailed information on the SA Engine architecture we refer to the following documents: