Publish and subscribe data flows
| Guide specification | |
|---|---|
| Guide type: | Wasm code |
| Requirements: | None |
| Recommended reading: | None |
Introduction
Data streams can be assigned unique names in SA Engine, called flows. Using flows streamed data can be passed between continuous queries in the local database, between SA Engine components, and between SA Engine peers. External systems can be interfaced using a publish-subscribe messaging pattern. The message pattern is used for interfacing SA Engine with distributed systems through Kafka and Azure Event Hub, distributed devices through MQTT, embedded systems through Canbus, Unix pipes, etc.
Examples of uses:
if you want to debug running continuous queries
if you want to retrieve data in real-time from SA Engine peers and edges in a federation
if you want to create graphical web visualizations
if you want to split a data stream to enable parallel processing
if you want to access real-time data streams from various kinds of sensors
if you want to access various kinds of distributed systems
Split and redirect streams
You can publish stream elements to a flow with the function
publish(Stream stream, Charstring flow)->Stream. Analogously, you can
receive stream elements from a flow with the function
subscribe(Chartrsing flow)->Stream.
As an example, let's start listening to the flow named flow0 by
calling with the subscribe function. It will not receive any stream
elements before flow0 is published.
subscribe("flow0");
Now, publish a synthetic data
stream siota(1,4)
to flow0 with the publish function.
publish(siota(1,4), "flow0")
We see that in this case the stream is split into two equivalent streams, the one where it is published and another one where it is subscribed.
If you want to redirect the published stream to a flow without
splitting it you can call the function sink(stream) that absorbs
stream elements of s without sending them further.
For example, let's start another flow named my_flow:
subscribe("my_flow");
sink(publish(siota(1,4), "my_flow"));
The figure below illustrates how the stream in the example above is
redirected by publishing it on the flow my_flow in a call to
sink().
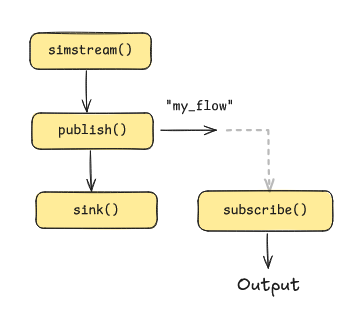
Redirecting a data stream into a flow with publish().
Experiment with starting and stopping the subscriber and publisher
above in different orders. Use simstream(pace) to generate simulated
streams.
Elements published to a flow with no subscriber will not be received anywhere.
A new subscriber to an active flow where elements already have been published will currently receive a stream of some lingering latest elements in the flow. This is a known bug. In the future the flow will be empty when the subscription is started.
Multiple subscribers
It is possible to have several subscriptions to the same flow.
For example, lets define some listener functions that return different
stream transformations on a flow named r_flow.
create function listener_1() -> Stream of Real
as select Stream of r * 3.0 + 10.0
from Real r
where r in subscribe("r_flow");
create function listener_2() -> Stream of Real
as select Stream of y
from Real r, Real y
where r in subscribe("r_flow")
and y = r*r - sin(r);
Now, start the listeners and plot the results, and keep the plots running.
//plot: Line plot
listener_1();
//plot: Line plot
listener_2();
Now when we redirect a stream to r_flow we will see that both
listeners will show the published data stream.
sink(publish(timeout(simstream(0.5),10),"r_flow"));
The figure below illustrates how the data stream in the example is redirection and split into two separate transformed subscriber streams.
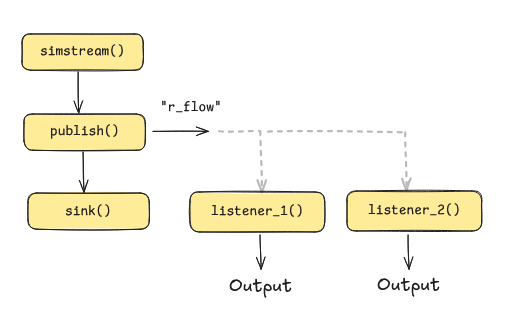
Redirected, split and transformed data stream.
What happens if you remove the call to sink()?
Publish from queries
publish(Stream s, Charstring flow) -> Stream takes a stream s as input
and returns the same stream s, which is also published on the flow.
The function can be used in queries.
For example, let's subscribe to flow fs and publish on fs
computations over elements of a siota() stream:
subscribe('fs')
select res
from Stream of Integer res,
Stream of Integer base
where base = siota(1,4)
and res = publish(base * 2, 'fs')
Here, the same elements of stream pub are both published on flow
fs and returned as the result from the publishing CQ.
Let's slighly change the publishing CQ:
select res
from Stream of Integer res,
Stream of Integer base
where base = publish(siota(1,4), 'fs')
and res = base * 2
In this case the elements 1,2,3,4 were published on flow fs while
2,4,6,8 was returned from the publishing CQ.
Querying subscribed flows
You can use the stream returned from subscribe(Charstring
flow)->Stream in queries as any other stream.
Example:
select i * 10
from Integer i
where i in subscribe('fs')
and i > 2
publish(siota(1,4),'fs')
Forcing publications
In should be noted that the stateful function publish(Stream s,
Charstring flow)->Stream only registers the flow name of the stream
s in the local database. It does not start publishing elements of
s on flow. To also publish the elements you can include the result
from (computations over) publish() in the result of the query, as in
the previous examples. Otherwise the elements of the flow will not be
published.
For example, the following CQ will not publish elements on flow
fs;
select true
from Stream of Integer base
where base = siota(10,14)
and exists publish(base, 'fs')
The reason for this is that the elements of stream base are not
extracted in the query result and therefore publish will not extract
and publish elements from siota(10,14).
To enfore publication you can use the function sink(Stream
s)->Boolean that extracts all elements from s and then returns
true.
This CQ will do the desired publication:
select true
where sink(publish(siota(10,14), 'fs'))
Merge flows
When subscribing to several flows, it is possible to merge them into
one single stream of elements with subscribe:merge(flows).
For example, start the following subscriber that merges the three flows "f1", "f2", and "f3", and keep it running.
subscribe:merge(["f1","f2","f3"]);
Now, publish different streams on the subscribed flows with different
paces using the synthetic stream
generator diota():
publish(diota(0.1,1,3), 'f1');
publish(diota(0.21,11,13), 'f2');
publish(diota(0.15,101,103), 'f3');
The problem with this is that the three successive calls to
publish() will publish the three streams in sequence. To publish
them in parallel use merge(Vector of Stream)->Stream:
merge([publish(diota(0.1,1,3), 'f1'),
publish(diota(0.21,11,13), 'f2'),
publish(diota(0.15,101,103), 'f3')])
With subscribe:merge_tagged(flows) you get a "bus stream" - the
elements are put into time
stamped vectors
with the flow name and the current time as number of microseconds
since epoc.
For example, start the following query and keep it running.
subscribe:merge_tagged(["f1","f2","f3"]);
Now when you run the following query you will see that the elements are
merged into a "bus stream" by the subscribe:merge_tagged() above.
merge([publish(diota(0.1,0,2), 'f1'),
publish(diota(0.21,10,12), 'f2'),
publish(diota(0.15,100,102), 'f3')])
Subscribe to flows on edges
When data is being published on an edge, it is also possible to subscribe to it from a client using subscribe and adding the edge name using @edge-name.
For example, the following will subscribe to the flow "my-flow" on the edge "my-edge".
subscribe('my-flow@my-edge');
This is similar to running the subscription on the edge, like below, but since the query is executed on the server it can continue running even if the connection to the edge is temporarily lost.
//peer: my-edge
subscribe('my-flow');
Subscribe to print output from edge
On each edge there exists a default flow OUTPUT which contains the output from print(). So by subscribing to the output flow we can get the print() output from any edge connected to the server.
subscribe('OUTPUT@my-edge');
Merge flows from multiple edges
The subscribe:merge and subscribe:pivot commands can be used to combine flows from multiple edges.
For example, the following will subscribe to the flow f1 on my-edge as well as on f2 on my-other-edge.
subscribe:merge(["f1@my-edge", "f2@my-other-edge"]);
While subscribe:merge merges the two flows into one stream,
subscribe:pivot creates a stream of vector, where the vector
contains elements from all streams.
Emit on flow
The function emit_on_flow() is in Unofficial state.
"Internal functions used by the system. No guarantee of when they are removed or added. Should not be used unless you know the risks."
The function emit_on_flow(Object o, Charstring flow) can be used to
send a single object o to a flow.
For example, start the following two subscribers and keep them running.
subscribe("f1")
subscribe('f2')
Then we run the following query which emits two different elements on two different flows, "f1" and "f2".
select i
from Integer i
where i in siota(1,10)
and exists emit_on_flow(i,'f1')
and exists emit_on_flow(10*i,'f2')
Performance compared to publish
It should be noted that using emit_on_flow() comes with a rather
large performance penalty compared to publish(). Each call to
emit_on_flow() needs to look up the flow publisher and set a bunch
of values for each element. Compare this to publish() which only
splits an existing stream. This means that using emit_on_flow() will
be order of magnitudes slower than using publish(). However, it is
useful for debugging data streams.
Further reading
Reference documentation of dataflow functions: Dataflow functions
Using dataflows to create multiplots of several streams: Advanced visualization