MLOps
MLOps is a set of practices that aims to deploy and maintain machine learning models in production reliably and efficiently. Most ML projects adhere to a sequence of steps required to ensure a successful project, usually referred to as the MLOps pipeline.

The process for each these steps is very similar between different ML platforms. However, most conventional platforms do not provide the interactivity that comes with SA Engine. For example, in the deployment phase they need to compile the entire software into a firmware package and deploy it as a firmware update on the device. This needs to be done each time a new model is deployed and has a few obvious drawbacks:
- It introduces a significant overhead in the compilation and packaging of the entire software and installing using Firmware Over the Air (FOTA). If FOTA is not available process takes even more time because you will need physical access to the device.
- The device needs to be shut down during deployment causing interruptions in production.
- It pins the analytics development cycle to the software development cycle. This means that models can only be deployed or updated when a new version of the software is installed on the device.
- It is risky since new firmware updates has the possibility of introducing bugs in critical systems on the device and if the FOTA process fails it might even brick the device causing costly interruptions and need for manual intervention.
- It does not scale well to large fleets of devices.
SA Engine on the other hand only need an initial install. Once it is installed and running on your device you can deploy models without updating the firmware.
The following sections explain how you can handle the different steps in the MLOps pipeline with SA Engine. The aim is to clarify what is possible with SA Engine and delineate between what SA Engine is built for and what parts of the MLOps pipeline should involve 3rd party software (which is equally important information). The MLOps process depicted in the figure above is commonly used and we choose to follow the structure in our explanation even though the interactive nature of SA Engine enables some improvements to the overall process.
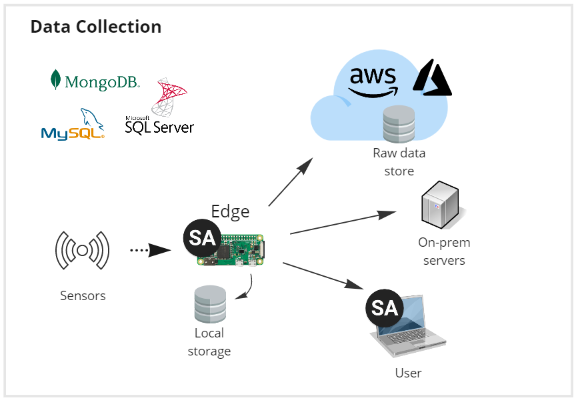
Data collection

Data collection is the process of collecting raw data from the device for analytical and model training purposes. SA Engine can use many modes of communication, such as Kafka and MQTT (see the Data C section for detailed information). It is interoperable with a lot of 3rd party data store cloud services, such as AWS or Azure, and can also store data in a range of common databases, such as SQL Server and MongoDB.
SA Engine's interactivity enables advanced data cleaning directly in the data collection step. With SA Engine, you can easily add complex preprocessing steps to the data collection pipeline to cater to any data cleaning needs. This can include techniques such as outlier detection, data imputation, and normalization. By performing data cleaning at the collection step, you can ensure that the data is in a usable format and that downstream analyses are accurate and meaningful. SA Engine's interactive workflow allows for rapid prototyping and experimentation, enabling you to quickly iterate through different approaches and models to find the best one for a given task. Overall, SA Engine's interactivity and advanced data cleaning capabilities help ensure that your data is clean and usable from the outset.
Data collection alt.
Data collection is the process of collecting raw data from the device for analytical and model training purposes. SA Engine can use many modes of communication, such as Kafka and MQTT (see the Data C section for detailed information). It is interoperable with a lot of 3rd party data store cloud services, such as AWS or Azure, and can also store data in a range of common databases, such as SQL Server and MongoDB.
SA Engine includes an interactive data stream management system that is designed to collect data in real-time. It can ingest and process data from multiple sources simultaneously, providing a unified view of the data that is easy to work with. Additionally, SA Engine's in-memory database provides fast access to large amounts of data, which is essential for real-time data collection.
The interactive nature of SA Engine makes it perfect for collecting data as it allows data scientists and developers to experiment with different data sources and parameters, leading to more efficient and effective data collection. With its small footprint and high performance, SA Engine is an ideal solution for companies that need to collect and process large volumes of data quickly and efficiently.
In summary, SA Engine is an excellent choice for companies looking to collect and process data in real-time. Its interactive nature and in-memory database provide fast and efficient access to large amounts of data, making it an essential tool for companies that need to collect and analyze data quickly and accurately.
Data analysis

Data analysis can be carried out directly on the live sensor streams on the edge device. The interactive nature of SA Engine makes it easy to visualize live streams or add analytics to live streams to get instant insights into data behavior without first having to record the data. This enables data analysis before doing data collection and you can get early insights to support the collection.
With the same query language used for recording data SA Engine allows you to define custom calculations and computations over data streams on any connected edge device. By allowing you to send custom queries to be executed on the edge device SA Engine enables you to do virtually any type of analysis.
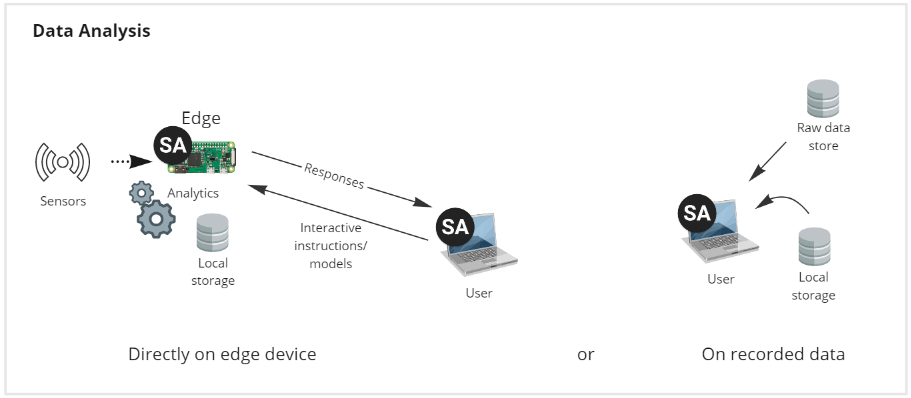
SA Engine also supports the classic approach to interact with recorded data by communicating with external data stores or data stored locally. You can either replay recorded data to simulate sensor streams or simply access static data from a file or a database.
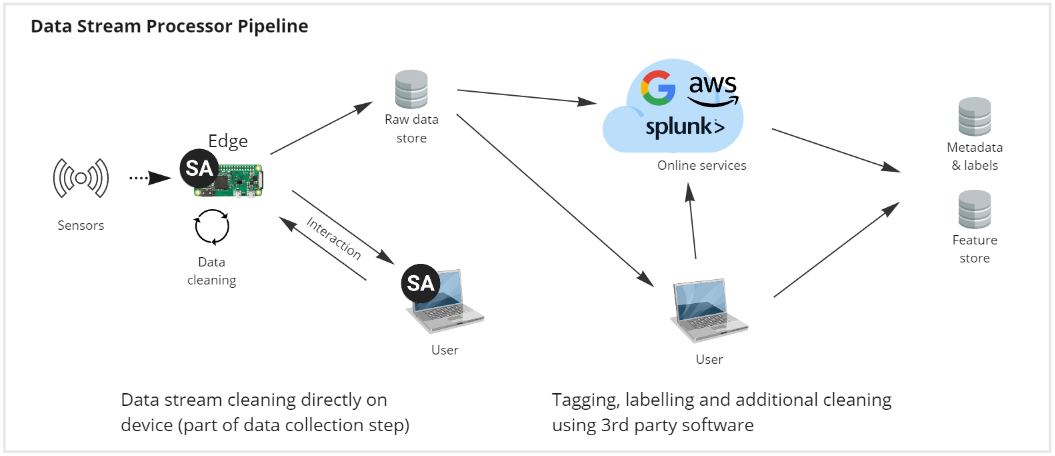
Data stream processing pipeline

SA Engine, with its capabilities as a main memory database, data stream management system, and computation engine, can be a valuable tool in the data stream processing (DSP) step of an ML-ops pipeline.
In the context of machine learning, data stream processing refers to the continuous analysis of data in motion, such as incoming data from IoT sensors, web applications, or other real-time sources. This real-time data presents unique challenges in terms of processing, storage, and analysis, and it requires specialized tools and technologies to handle effectively.
SA Engine can assist in this process by providing a high-performance, low-latency, and scalable data stream processing infrastructure. Its in-memory database capabilities allow for rapid access and processing of large amounts of data, while its data stream management system provides the ability to efficiently and effectively manage data streams as they are ingested. Additionally, its computation engine enables the processing of complex computations in real-time, providing insights and predictions on the fly.
In an ML-ops pipeline, SA Engine can be used as a key component in the data stream processing step, providing the infrastructure to support real-time model training and deployment. For example, SA Engine can be used to collect and process sensor data from an IoT device, run a pre-trained machine learning model on the data, and provide immediate feedback and predictions to the device or other downstream applications.
Overall, SA Engine provides a powerful platform for data stream processing, with its capabilities as a main memory database, data stream management system, and computation engine making it an excellent choice for handling the real-time data requirements of an ML-ops pipeline.
In addition to its other features, SA Engine provides an interactive workflow that enables users to interact with the data and obtain insights in real-time. The interactive workflow allows users to define and modify the data processing pipeline on the fly, enabling them to make adjustments and optimize the pipeline as needed.
For example, in the context of an ML-ops pipeline, the interactive workflow can be used to fine-tune machine learning models by adjusting parameters and analyzing the results in real-time. This enables the user to quickly iterate and refine the model until it meets the desired level of accuracy and efficiency.
The interactive workflow also allows for the easy creation of ad-hoc queries and reports, providing users with the ability to explore the data and generate insights on the fly. This is particularly valuable in scenarios where time is of the essence and the ability to respond quickly to changing conditions can make all the difference.
Overall, SA Engine's interactive workflow provides users with a powerful tool for real-time data analysis and processing, enabling them to make informed decisions and take actions quickly and confidently.
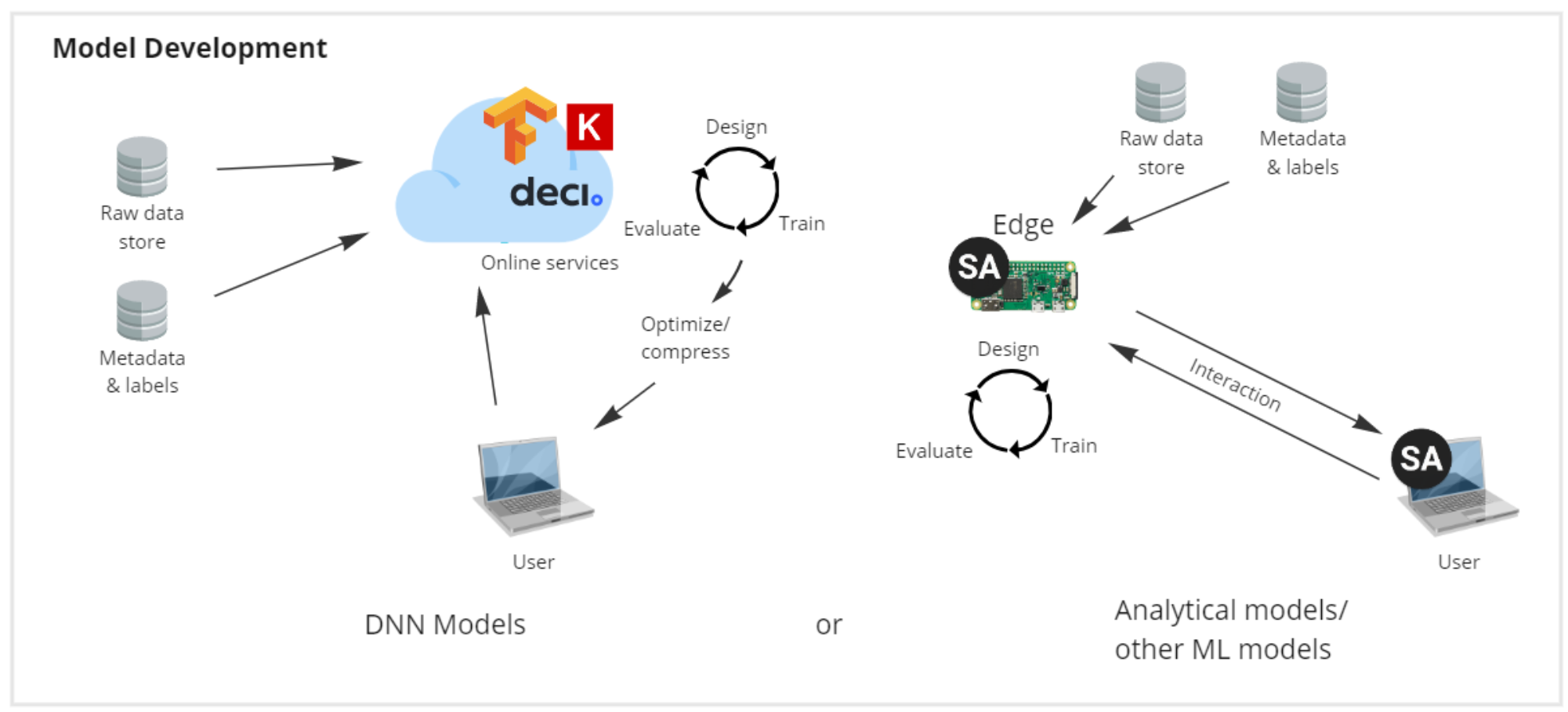
Model development

Model Development can be regarded as the combined procedures of ML Design & Training, Estimation & Evaluation, and Optimization & Compression. With the recent success of Deep Neural Networks (DNNs) in the field of Machine Learning, there has been a lot of focus on technologies for DNN model development. Large corporations have spent massive amounts on building and maintaining both software and hardware specifically invented for designing and training DNN models.
When building and training ML models we want to leverage the progress of DNN-related resources in the field of ML and therefore we need to delineate between DNN models and other ML models, which has not benefitted as much from the recent DNN surge. The design, training and optimization of DNN models should therefore utilize the huge amount of external resources that is tailored to that specific purpose while using SA Engine to design and train other ML models and analytical models. However, SA Engine supports some degree of training DNNs on edge devices.
The design, training and optimization of analytical models and ML models other than DNNs benefit from the interactive nature of SA Engine. This means that models can be developed and trained directly on the edge devices. Either on the fly on live sensor streams or by the traditional process of collecting/labelling data and offline training.
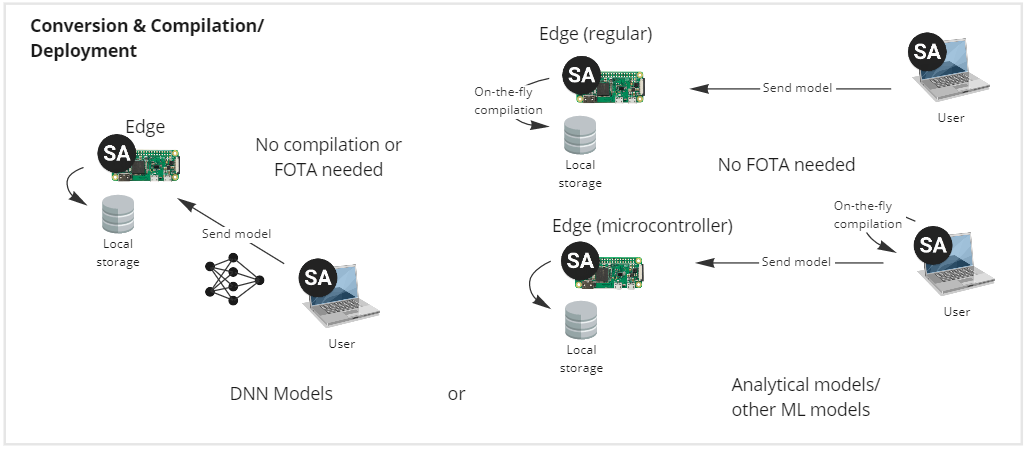
Conversion & compilation (deployment)

Conversion and Compilation is traditionally the process of adjusting the model for the target hardware, compiling the software bundle into a firmware update and replacing the firmware on the device.
DNN models
Deploying a DNN model is simply using SA Engine to transfer the model binary to the edge device together with the integration code. There is no need to bundle the model into a firmware release or do any kind of firmware update on the device. Both deploying new DNN models and updating existing DNN models can thus be done fast and efficiently while the edge device is running live in production, with minimal or no interruption.
Analytical and other ML models
Deploying analytical models and ML models that are not DNNs is done in two ways depending on whether the edge device is a microcontroller or a regular edge device.
For microcontrollers the model code is optimized and cross-compiled to machine code on a separate SA Engine instance used to communicate with the SA Engine instance on the microcontroller. The optimized and compiled machine code is then transferred to the edge device. All this is done using just-in-time (JIT) compilation when running the model code in the user interface.
For models on edge devices that run the full version of SA Engine, the models are sent to the edge device and optimized and compiled on the device before execution. Like when deploying models to microcontrollers, this is also done using JIT compilation when running the model code in the user interface.
Since SA Engine is an engine running on the edge device, neither microcontrollers nor edge devices with the full version SA Engine need to have their firmware updated when deploying models. Model deployment can therefore be done seamlessly while the device is running live, causing minimal or no interruption to production flow.
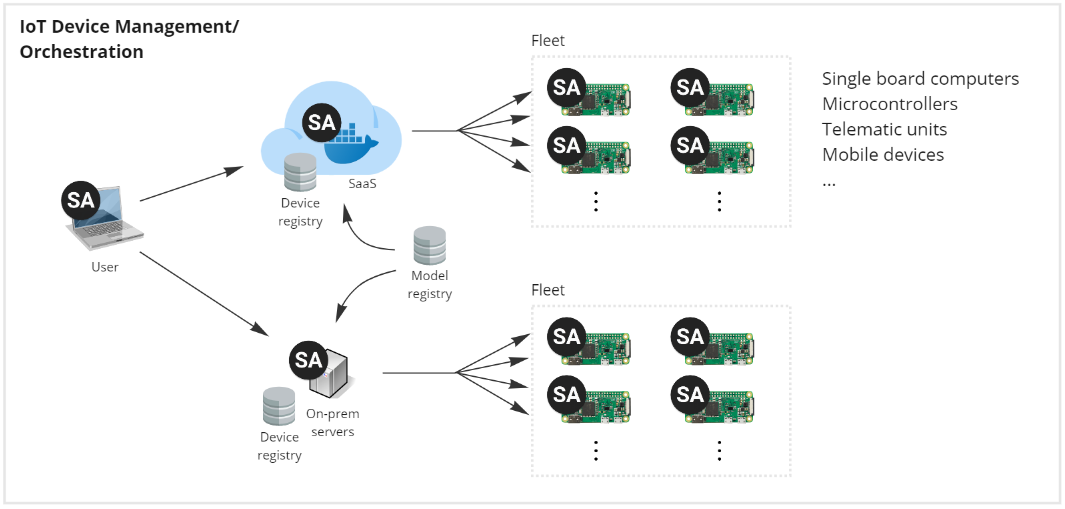
IoT device management (orchestration)

SA Engine offers powerful capabilities for orchestrating and managing devices in an IoT setting. With its small footprint and efficient data processing, SA Engine can be deployed on edge devices, allowing for real-time data processing and analysis.
SA Engine provides an interactive workflow for rapid prototyping and experimentation, enabling engineers and data scientists to quickly iterate through different approaches and models to find the best one for a given task. Once a model is developed, SA Engine can be used to orchestrate its deployment to the necessary devices in the IoT network.
SA Engine allows for deployment, testing, and orchestration based on parameters, ensuring that only the necessary devices receive updates, saving bandwidth and storage. The deployment process sends only the model to the engine running on the device, separating the firmware and model update processes.
With SA Engine, users can access the full distributed system of engines to run queries over central metadata for selecting edges to deploy to, or query populations of edges to decide whether to deploy a model to those edges. This simplifies the orchestration and management of devices in an IoT setting, improving efficiency and productivity.
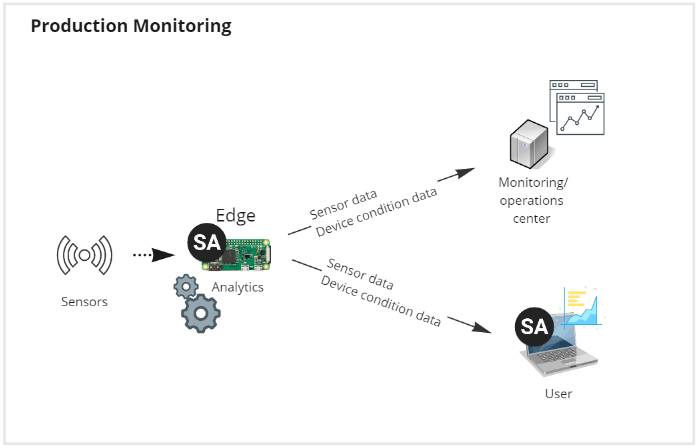
Production monitoring

Production monitoring is essential for any manufacturing or industrial process. The ability to monitor the production process in real-time and identify any issues as they arise is critical for ensuring efficiency and productivity. This is where SA Engine comes in, offering a powerful solution for smart models monitoring assets and streaming results back to monitoring centers.
SA Engine is designed to handle real-time data streams, making it an ideal tool for production monitoring applications. Its interactive workflow enables rapid prototyping and experimentation, allowing engineers and data scientists to quickly iterate through different approaches and models to find the best one for a given task.
One of the key features of SA Engine is its ability to stream results back to monitoring centers. This enables stakeholders to monitor production processes remotely and make informed decisions quickly. With SA Engine, you can monitor assets in real-time and respond quickly to any issues that arise, ensuring that your production process runs smoothly and efficiently.
Furthermore, SA Engine can be easily integrated with any other backend system. This means that you can incorporate SA Engine into your existing workflows and tools, allowing you to process and analyze data from a wide range of sources in real-time.
SA Engine is a powerful tool for production monitoring applications, providing real-time data processing and analysis, an interactive workflow for rapid prototyping and experimentation, and the ability to stream results back to monitoring centers.